ISUCON12予選に参加しました!結果、スコア自体は予選ボーダー通過していましたが追試で失格でした 😭😭😭
チームいすもなで参加 もなちゃんすまん…
通過した気満々で参加記事書いてましたが、供養のため投稿します。
なお過去にはISUCON9, 11に参加していずれも上位30~50%tileくらいに留まったので、今回はその反省も踏まえつつ準備しました。
今回の方針
Go使う
大きな変化はこれです。ISUCONで使う言語は実質Ruby とGoの二択だと思ってます (他の言語はISUCON向けの情報が充実してない印象) が、これまでは業務でGoを使ったことがないのでRuby を選択してました。ただしRuby は以下のつらみが見過ごせませんでした:
諸々のツール (profilerなど) が古く使いづらい
unicorn /pumaの設定などチューニング項目も増える静的解析が弱いゆえにデプロイしてからエラーに気づくことも多い
またこれは曖昧な情報なのですが、Goの方がやはり処理能力は高い気がします。ISUCON11予選をRuby とGoで解いたのですが、Ruby でかなり苦労して達成したスコアをGoだと軽々と乗り越えられるなあという感じでした。
結局Goは業務で使ってなくても2〜3日でなんとなくいじれるようになりましたし、上記Ruby のつらみが全て克服できるので、最高でした。
ソロ参加
今回は準備がしっかりできるか怪しかったので、迷惑がかからないよう1人で参加しました。後述しますが、これはこれで良い点も多かったです。
準備
ISUCON11予選をGoで解き直しました。解き直す時はこれを見ながら取り組んだのですが、とても良かったです。
isucon.net
ツワモノの思考法がよく分かりますし、あまり突拍子もない事はしなくても予選通過できるのだということを示してくれています。今回12予選を解いているときもこの思考法はめちゃくちゃ参考になりました。
11予選を解くとISUCONに必要なGoの知識は大体インプットできました。ISUCONはN+1解消とバルクインサートとオンメモリキャッシュの書き方だけ抑えておけば、なんとかなる気がします (フラグ)。
前日はお菓子と食料を用意した上でよく寝ました。
当日
8:00 起床
興奮して早めに起きてしまいました。人の頭は起きてから2時間後くらいからフル稼働始めるものらしいので、ちょうど良かったのかもしれません。
10:00 開始
開始後1時間は割と定形作業なので、マニュアルを作っておきました。おかげで落ち着いて作業できるので良かったです。コマンドも事前にここに まとめています。(とはいえ今回はdocker-composeで動くので準備していたデプロイスクリプト が使えなかったりsqlite の対策は何もしてなかったりなど、やはり想定外はありますね…)
ソロISUCON 道標 · GitHub
やや特異な点としては、初手決め打ちでMySQL サーバーとアプリサーバーを分離する点です。過去の傾向からこれは確実に必要になる施策のため、またサーバーを分けることで htop でそれぞれの負荷を見やすくなるため、何も考えずに初手で実施しています。
ちなみに一点困ったのは、マニュアルに記載されていた 方法ではポート443のSSH ポートフォワ ーディングができなかったことです。社用Macbook で参加していたので、何か制限があったのかもしれません。解決に時間がかかりそうなので、フロントが必要になったら深堀りしようと後回しにしました。しかし、今回は結局最後までフロントエンドを見ずに終わってしまい、これが良くなかったです(後述)。
諸々のログも取れるようにして、この時点でのスコアが4117です。
11:00 コードやログを読み始める
ログを見ながら、取り組みやすい改善を入れていきます。今回の目標はそれなりに良いスコアを取ることだったので、実装が難しい大それたことは全て避けました。結果的には、たまたまこ れが功を奏したようです。(MySQL 載せ替えで苦労した人の話を伺う限り)
11:05 MySQL にインデックスはる
MySQL のスロークエリログに出ていたクエリに全てインデックスをはりました。sqlite はログを取れてないので、一旦無視です。
なお従来のISUCONだと01_Schema.sql のようなファイルがあって、それが POST /initialize のたびに反映されていたのですが、今回はありませんでした(!)。このためMySQL のスキーマ はコード管理せず、直接DBをいじってます。変更取り消したいときダルそうだなと思いましたが、結果的にはMySQL にあまり触れなかったので問題なかったです。
11:40 まとめて採番できるように
スロークエリログ を見るとダントツで採番クエリが発行されていたので、とりあえず手を付けました。
採番は前職の時によく考えた問題です。現状では1リクエス トの中で複数の採番をするために1つずつ採番クエリを発行していたので、まとめて採番するようにします。この記事の方法を丸パクリしました。 MySQLで採番機能(シーケンス)を実装する方法を整理する - Qiita
ストレージエンジンは特にデメリットもないのでMyISAM にしましたが、今回は全体的にトランザクション が使われてないので、InnoDB でも大差ない気はします。
とりあえずまとめて採番できるインターフェースにしつつ 、これだけでは何も性能は変わらないのですが、呼び出し側の改善はn+1の解消なども関わりそうだったので後ほど実施することにしました。
12:20 SQLite にインデックスはる
SQLite 初見だし実装力にも自信がないので、SQLite はそのままにしておこうと考えました。付け焼き刃の対策として、インデックスだけは貼りました 。
SQLite は全く計測できてないので、発行される全てのクエリに対して必要なインデックスを張った形になります (計測せよとは…)。/initialize も十分間に合ってました (約10秒)。これでスコア5107になりました。
さらなる最適化としてtmpfsを考えましたが、ググった限り意外と導入に時間掛かりそうなのと、負荷上がったときにもしメモリ溢れたら詰むなあと考えて止めました。
後、ビューワーに DB Browser for SQLite というツールを使いました。初めて使う道具でCLI は難しく、やはりGUI が良いですね。
12:53 retrievePlayerのバルク化, competitionScoreHandler のN+1解消
プレイヤーの詳細をsqlite から取得する retrievePlayer 関数ですが、これがあちこちでN+1問題を引き起こしていました。このため、複数プレイヤーを一括取得する retrievePlayers 関数を作り導入していきます。
ちなみに実はここで実装した関数がバグっていて、後々不穏な挙動を引き起こします。
ひとまずはそこそこリクエス トが来ていて実装も単純な competitionScoreHandler 関数に導入して、N+1問題を一つ潰しました 。
これでスコア6994 。
13:13 competitionRankingHandler のN+1解消
同様のアプローチでN+1を潰します 。Go + Golandで挑んでますが、やはりコーディングはしやすいです。コンパイル が通ったら大体ちゃんと動くので、今回は全体的にほとんど詰まることなく実装を勧められました。
これでスコア8040。
13:41 CSV 入稿をバルクインサートに
そこまでアクセスがないエンドポイントなのでスコアに効くかな?と思いつつ、わかりやすい改善ポイントなので着手しました 。思いの外スコア上がった印象です。ルールをよく見ると 、このエンドポイントは他のものに比べて10倍のスコアがあるので、実はかなり重要だということに後半から気づきました。
なお、ここで冒頭に作ったバルク採番の仕組みが有効に使えていて、採番クエリもかなり削減できました。
ここ以降勢いづいたのでスコアの記録があまりありません。ベンチマーク 履歴は試合終了後も見えるかなと思ってましたがそんなことはなかったです><
14:36 プレイヤーのオンメモリキャッシュ
現状いろいろなエンドポイントが retrievePlayer を呼んでいるので、おそらくキャッシュが有効だろうと考えました。SQLite の計測ができていないので割と勘ベースではあります。{tenantId}#{playerId} の文字列でキャッシュすることにしました 。
disqualified の状態がたまに変化するので、その時はキャッシュをクリアする 必要があります。
14:45 コンペティション のオンメモリキャッシュ
脳がオンメモリキャッシュに慣れたので、ついでに retrieveCompetition もキャッシュ化しました
10分くらいでできそうだったので何も考えずに実施しましたが、実はこれがかなり効きました。今考えるとコンペティション はユーザー間で共有されるのでキャッシュが有効なのは当然な気もします。
これでスコアが16056になりました。 この辺りでリーダーボードを見て、これ予選突破できるんじゃねと妄想してドキドキしました。
15:04 competitionScoreHandlerの採番を改善
またまた採番のバルク化 です。シンプルに効きます。
ちなみに講評で知りましたが、UUID化しても問題なかったらしいです。API レスポンスの形式は変えちゃだめだと思ってたのですが、IDのフォーマットは何でも良かったようですね。ただしUUIDは長い文字列なので他の処理が重くなる可能性もあるとのこと。
15:16 プレイヤーのスコアを重複保存しない
CSV 入稿時にプレイヤースコアを保存しますが、実は必要なのはプレイヤーごとの最高スコア (=CSV で最後に出てくる行) だけでした。重複排除して保存するようにします 。
これだけだとバルクインサートの数が少し減るだけなのであまり効かないのですが、これにより次のN+1問題を解消することができます。
15:26 playerHandlerのN+1解消
プレイヤーがコンペティション ごとにスコアを1行しか持たなくなったので、プレイヤーの全スコアをまとめて取ってこれるようになりました 。
15:54 ランクのソートをSQLite 側で実行する
こうなるとソート処理もアプリ側でやるほど複雑ではなくなるので、Sqliteでインデックスも使いながら実行します 。
だいぶ実装がシンプルになり気持ちが良いですね!
16:15 減点要因を直す
ベンチの結果を見て、やたら減点されている (-20%とか) ことに疑問を感じていました。
Score Breakdown: base=19344, deduction=3288
当初は負荷が高いからロック競合起きているのかな―と思いましたが、さすがにここまで解消しないということはアプリのバグのようです。エラーが起きるエンドポイントはベンチマーカーが教えてくれるので、アプリのログを見ながら原因を探します。
結果的には、 プレイヤーをバルク取得する retrievePlayers 関数の実装がだめだったようです。クエリのIN句が長すぎる場合に落ちるようでした。とりあえず1000件ごとにクエリを分けるように修正してみた ところ、エラーが解消されました。SQlite のクエリ長に上限があるようですね。
アプリのログで write: broken pipe という旨のエラーが多発していたので、これも疑ったのですが、減点数の割にログ件数が多すぎたので無関係と判断しました。クライアントがレスポンスを受け取る前に切断すると起きる現象のようですが、ベンチマーカーがそのような実装になっていたんでしょうか?
16:28 billingReportByCompetition の改善
このエンドポイントも10倍のスコアを持つので、何かしら改善しようと思いました。とはいえ結構複雑な実装なので、簡単に手を入れられることは少なそうです。とりあえずコンペティション が終わってないときは何の計算もしないことが分かったので、早期リターンするようにしました 。テナントDBの中を見る限り finished_at がNULLの行は半分くらいあったので、そこそこ効いたはずです(スコア差分うろ覚え)。
ここまでで22593です 。
16:40 3台目を使う
今までのサーバー利用状況は、1台目: nginx+app 2台目: mysql で3台目が完全に遊んでました。かわいそうだったので、 1台目からappを切り離して3台目に渡します。
今回は nginx の負荷がかなり軽微 (CPU 5%程度) なので今度は1台目が遊びがちになりますが、それでも多少スコアが上がりました。23227 もしかすると誤差の範囲だったかもしれません。
仕事を与えられて生き生きとするisu3
17:00 flock の見直し
正直ここまででできることが尽きたので、最後に今まで見て見ぬ振りしていたflock をなんとかしようと考えました。よく見るとこれまでのN+1解消などにより、多くの箇所でflock を取る意味がなくなっているようです。不要そうなところを消していきました。
未だに解せないのは、消すことでスコアが下がる場合があった (減点ではなく元スコアが下がる) ことです。どちらかというと整合性エラーが起きるのかなと予想していたので、これは意外でした。ここまで17:10くらいで時間が余っていたので、flock をつけたり消したりしてベンチマーク を取り、最高のflock パターンを残しました。
講評を聞いて、トランザクション の代わりにflock を使っていたのだと意図を知りました。ISUCONは設定上の開発者がヌケている前提があるので、それを意識して解法をメタ読みするのが重要かもしれないですね。
ベンチガチャ
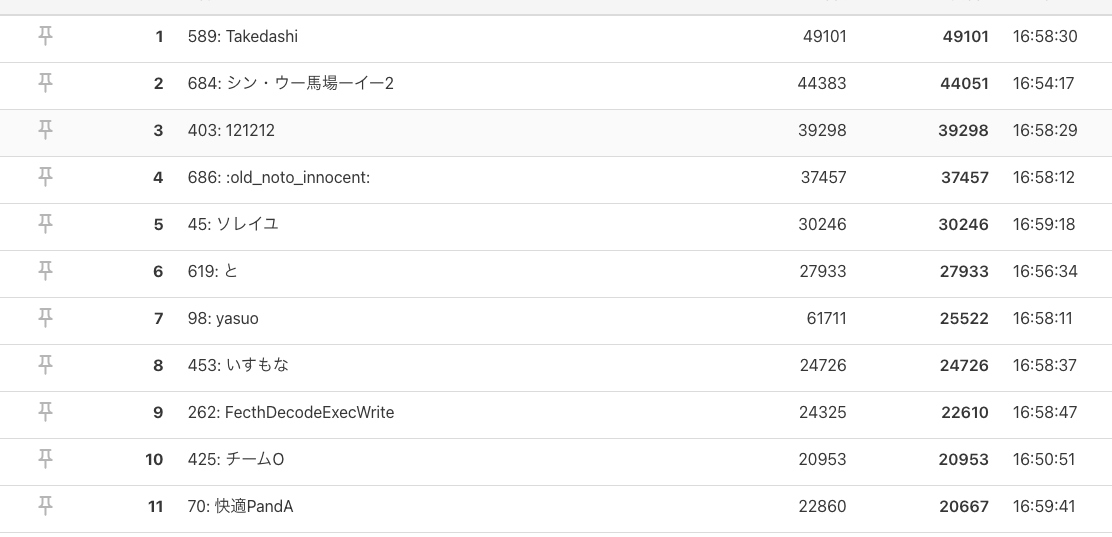
終盤のリーダーボードで8位だったので、ワンチャンあるなと欲がでました。
ベンチマーク を回すたびにスコアが ±10% くらい変動するので、終盤30分くらいひたすらベンチマーク を回し続けました (もうこれ以上は簡単にできる施策がなさそうだった)。17:50くらいにSSR くらいのスコアを引けて、最終スコア 28957 でフィニッシュです。SQLite をそのまま残すパターンとしてはできる限りやれたんではと思うんですが、どうなんでしょう。
結果
運営チームの追試によりブラウザチェックで失格…!失格!!!
原因はこれです:
var playerCache *cacheSlice
var competitionCache *cacheSliceCompetition
func initializeHandler(c echo.Context) error {
playerCache = NewPlayerCacheSlice()
competitionCache = NewCompetitionCacheSlice()
}
おわかりいただけたでしょうか。
これでは POST /initialize を実行せずに各エンドポイントが叩かれた場合に各キャッシュがnull pointer referenceでpanicします。ベンチマーク では起こり得ない挙動だったので、気づけませんでした。
フロントエンドを無視したのが仇となったと思います。最近はnull安全なTypeScript ばかり書いていたので、私のヌルポセンサーが劣化していたというのも原因の一つでしょう。また、そもそも追試の項目をよく確認しておらず再起動後にベンチマーク を回すだけに留まっていたという詰めの甘さも問題でした。
ここはチェックリストで改善できるはずなので、次回は気をつけます。
振り返り
結果は残念でしたが、ソロ参加は次の点で意外と良かったです。
デプロイの競合もマージコンフリクトもない
このため開発フローがかなり単純化 できる
一切会話しなくて良いので集中できる
ダメ元感があるのでプレッシャーも減る
ただし絶対的にできる作業量は減るので、限界は感じます。よく連携できた3人チームにはまず勝てないと思います。
Goも最高でした。今思えばRuby はある種のしばりプレイだったんだなと思います。欲を言えばNULL安全ならもっと良かった…………。来年参加するときはもう少し慣れておきます。
今回失格に終わったのはメッチャクチャめちゃくちゃ残念ですが、これを戒めとして今後も慢心せず精進していきます!運営の皆さまありがとうございました!!