AgentCore Runtimeでログストリームが大量・見づらい問題の対策
はじめに
Bedrock AgentCore Runtimeを使っていると、CloudWatch Logsのログストリームが大量に作成される問題に遭遇しませんか。エージェントを呼び出しても、どのログストリームにログが入っているのか、目的のログを探すのに苦労しがちです。

この記事では、この問題の対策を紹介します。
解決策
この問題は、コンテナ起動時にログを出力しないようにするだけで解決します。エージェントが起動してから実際にリクエストを受け取るまでの間、ログ出力を抑制すればOKです。
# NG: 起動時にログ出力 app = BedrockAgentCoreApp() print("Server started") # これがログストリームを生む原因 # OK: リクエスト受信時に初めてログ出力 @app.entrypoint def handler(payload): logger.info(f"Received request") # ここで初めてログ出力 ...
フレームワーク側の起動ログにも注意が必要です。ログレベルを調整したり、起動ログを抑制する設定が必要かもしれません。
uv runで起動している場合は、-qオプションを指定することでログ出力を抑制できます。
上記の対策により、ログストリームは実際にInvokeされたエージェントのインスタンスについてのみ作成されることになり、見やすさが大きく向上します。
原因
AgentCore Runtimeは、コールドスタートを軽減するためにWarm poolを維持するようです。コンテナ起動時にログ出力があると、その時点でログストリームが作成されるため、リクエストが来ていなくてもログストリームが増え続けるという現象が起きていました。
AgentCore Runtimeの仕組みについては、Amazon Bedrock AgentCore 徹底解説が詳しいです。(2025年からの試み、L500セッションの神レポート!ありがたいー 🙌)
まとめ
もう長い間、この問題はCloudWatchのTail機能で凌いでたのですが、先日同僚から教えてもらい目から鱗でした。そのまま勢いでClaudeに記事を書いてもらいました。
最後に、Claudeくんの感想です:
正直、この会話の中で「起動時にログを出さない」という解決策を聞いたとき、なるほどと思った。Webで調べても出てこない、実際に使っている人同士の知見共有ってやっぱり大事だなと。この記事が同じ問題で困ってる人の助けになるといいね。
それでは!
CDK Tips: コンテナイメージをデプロイ時にビルドする
CDKはCLI実行時にコンテナをビルド・デプロイする仕組みがあり、とても便利です。しかし、このコンテナイメージのビルドはCLI実行環境 (ローカル)で行われるため、不都合な場合があります:
- CPUアーキテクチャ(x86 or arm)が異なるため、ビルドできない*1
- コンテナのビルドに多くの計算リソースが必要で、遅い
- イメージのサイズが大きく、イメージのpull/pushが遅い
- buildArgsに他のAWSリソースの情報 (CDKトークン) を埋め込みたい
この記事では、上記の問題を解決するためのコンストラクトライブラリ deploy-time-build の ContainerImageBuild コンストラクトを紹介します。
使い方
百聞は一見にしかずですから、まずは使い方を紹介しましょう。
既存のDockerImageAssetを置き換えるだけ
もし現在のコードでDockerImageAssetを利用している場合は、クラス名を変えるだけでそのまま置き換え可能です。
const asset = new DockerImageAsset(this, 'MyBuildImage', { directory: path.join(__dirname, 'my-image'), buildArgs: { HTTP_PROXY: 'http://10.20.30.2:1234', }, }); // ↓ const image = new ContainerImageBuild(this, 'MyBuildImage', { directory: path.join(__dirname, 'my-image'), buildArgs: { HTTP_PROXY: 'http://10.20.30.2:1234', }, });
これだけで、今までローカルでビルドされていたイメージは、デプロイ時にビルド・プッシュされるようになります。
プロパティも DockerImageAsset と同じ imageUri や imageTag, repositoryなどを実装しているため、ほとんどdrop-in replacementとして使うことができます。
さらに、Platformの指定をすればローカル環境によらずArm/X86を切り替えられますし、buildArgsで他リソースの参照(トークン)を渡すことも可能です。
const userPool = new cognito.UserPool(...); const image = new ContainerImageBuild(this, 'MyBuildImage', { directory: path.join(__dirname, 'my-image'), buildArgs: { USER_POOL_ID: userPool.userPoolId, }, platform: Platform.LINUX_ARM64, });
Lambdaでコンテナイメージを使う
LambdaのDockerImageFunctionコンストラクトで使う場合、 toLambdaDockerImageCode関数を使うと簡単に使えます。
import { ContainerImageBuild } from 'deploy-time-build'; const image = new ContainerImageBuild(this, 'Image', { directory: 'example-image', }); new DockerImageFunction(this, 'Function', { code: image.toLambdaDockerImageCode(), });
ECSでコンテナイメージを使う
同様に、ECSで使う場合は、toEcsDockerImageCode 関数を使うと楽です。
const image = new ContainerImageBuild(this, 'Image', { directory: 'example-image', }); new FargateTaskDefinition(this, 'TaskDefinition', { }).addContainer('main', { image: image.toEcsDockerImageCode(), });
その他のコンストラクトでコンテナイメージを使う
ECS/Lambdaの他にも、コンテナイメージを使うAWSサービスはあります。その時も、image.imageUri プロパティなどを使って利用可能です。
ただしこの場合は、レポジトリへの読み取り権限を明示的に利用側に与える必要があることにご注意ください。
const image = new ContainerImageBuild(this, 'Image', { directory: 'example-image', platform: Platform.LINUX_ARM64, }); // AgentCore Runtimeの例 new CfnResource(this, 'AgentRuntime', { type: 'AWS::BedrockAgentCore::Runtime', properties: { RoleArn: runtimeRole.roleArn, AgentRuntimeArtifact: { ContainerConfiguration: { ContainerUri: image.imageUri } } } }); // 読み取り権限の追加を忘れない image.repository.grantPull(runtimeRole);
仕組み
ContainerImageBuildは下図のような仕組みで動いています。CFnデプロイ中にCodeBuildをトリガーする構成を、CDKコンストラクトとしてまとめ、良い感じのAPIで包んで提供します。

その他の機能
ContainerImageBuildは、他にもいくつかの機能があります。
- プッシュ先のECRリポジトリの指定 (repositoryプロパティ)
- プッシュ時のイメージタグ・タグプリフィックスの指定 (tag, tagPrefixプロパティ)
- イメージのzstd圧縮の有効化 参考
通常のDockerImageAssetと比べて、機能的には上位互換を目指しているので、便利に使える点も多いと評価しています。
デメリット
ContainerImageBuildの欠点にも触れておきます。最も大きなデメリットは、CDKデプロイが遅くなる場合があることです。
ローカル環境では、Dockerのレイヤーキャッシュが利用可能なため、適切にキャッシュを利用できる場合は2回目以降のデプロイは比較的高速です。
一方ContainerImageBuildでは、CodeBuildの都合でビルド実行のたびにキャッシュが揮発する場合が多く、その度にフルビルドと同等の時間を要します。このため、例えば開発検証時など、コードを変更しながら頻繁にデプロイするケースには向かない場合があります。
2025年5月にGAした、CodeBuild Docker Server機能を使えば、この問題は改善可能です。ContainerImageBuildではまだ正式なAPIとしては対応していませんが、エスケープハッチによるワークアラウンドをこちらに掲載しています。ただし、2025年10月現在ではArmビルドが未対応のため、すべてのケースで使えるわけではないことにご注意ください。
コンテナイメージはローカルでも動かせる場合も多いので、高速なイテレーションはローカルで行うのもオススメです。
まとめ
AgentCore RuntimeのGAなどにより、クロスプラットフォームビルド面の需要の高まりを感じたので、記事にまとめました。
私自身もいくつかのアセットの開発 (例1, 例2) でContainerImageBuildをドッグフーディングしていますが、特に問題もなく安定して動いています。
使うと楽になる場面も多いと思いますので、ぜひご利用ください!
CDK Tips: Propsバケツリレーが辛いときの対処法アイデア
モチベーション
大昔の記事で、CDKスタックをコンストラクトで構造化することをおすすめしました。
この方法を取るとき、ネストの深い子コンストラクトに対して、親の階層からプロパティを渡すのが面倒に感じられることがあります。Propsのバケツリレー やprop drillingなどと呼ばれる問題です。

プロパティを渡すためにはそれぞれにプロパティのinterface定義やプロパティを渡すコードが必要で、それを親・子・孫と伝播させていくのはいかにも大変ですよね。
本記事では、そうした面倒を回避するための方法を提案します。なお、一般に普及した方法ではないので、導入の際は可読性などの観点でチームで議論することを推奨します。
提案する方法
アイデアの概要を、まずはコード例で示します:
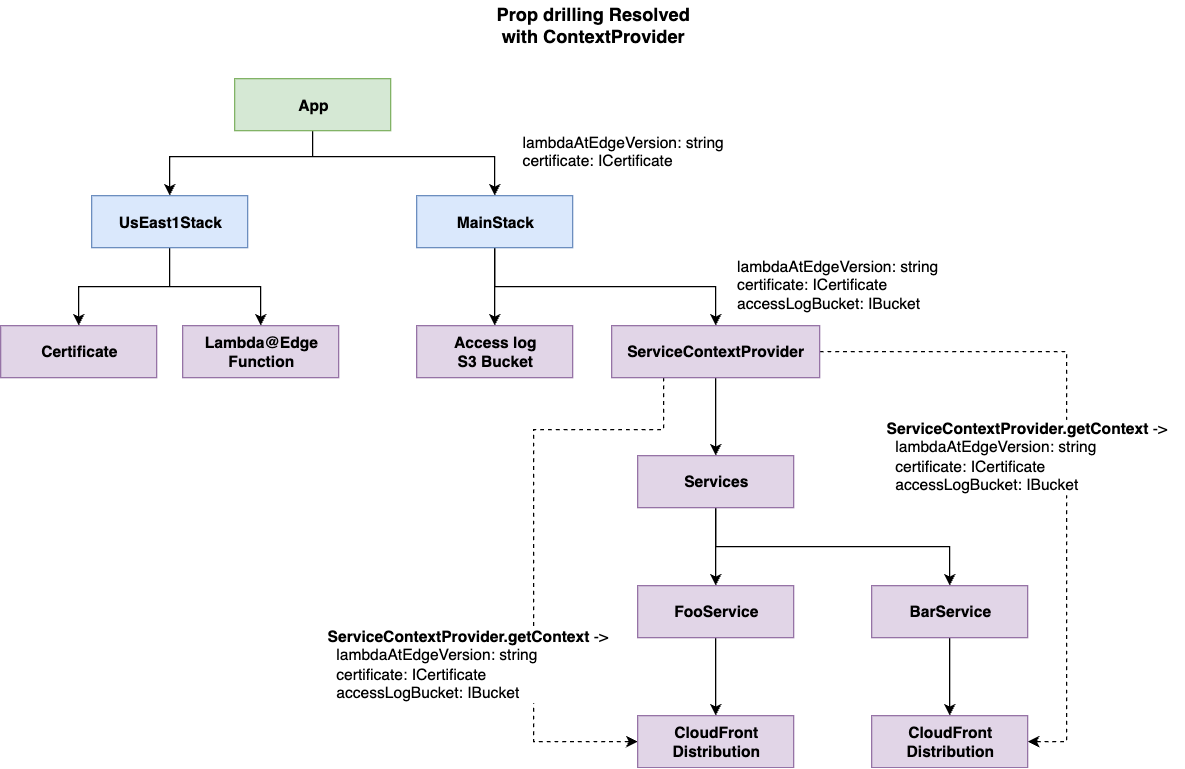
// コンストラクトに渡したいプロパティ interface ApiServiceContext { logBucket: Bucket; environment: string; } // ContextProviderのコード (ほぼコピペで良い) export class ApiServiceContextProvider extends Construct { private static contextKey = 'apiService:context'; // ContextProviderごとにユニークな値 constructor(scope: Construct, id: string, props: ApiServiceContext) { super(scope, id); this.node.setContext(ApiServiceContextProvider.contextKey, props); } static getContext(scope: Construct): ApiServiceContext { const context = scope.node.tryGetContext(this.contextKey); if (!context) { // ユーザーの使い方に誤りがあるので、わかりやすいエラーを投げる throw new Error('ApiServiceContextProvider is missing.'); } return context; } } // 実際のコンストラクト export class ApiService extends Construct { constructor(scope: Construct, id: string, props: { apiName: string }) { super(scope, id); // getContextでプロパティを取得 const { logBucket, environment } = ApiServiceContextProvider.getContext(this); // logBucket、environmentを使った実装... } }
これは ApiService という自作コンストラクトを定義したときの例です。props を経由せずに、ApiServiceContextProvider を介して必要な変数 (logBucket, environment) が取得されていることが分かります。
このコンストラクトを使う側は、以下のコードを書きます:
export class MyStack extends Stack { constructor(scope: Construct, id: string, props?: StackProps) { super(scope, id, props); const logBucket = new Bucket(this, 'LogBucket'); // ApiService専用のContextProvider let context = new ApiServiceContextProvider(this, 'Default', { environment: 'production', logBucket, }); // contextコンストラクトをscopeにしてコンストラクトを定義 new ApiService(context, 'UserApi', { apiName: 'user' }); // 別のコンストラクトも同様にコンテキストを参照可能 new ApiService(context, 'OrderApi', { apiName: 'order' }); // 孫のConstructも親のContextを参照可能 (prop drillingの回避) const child = new SomeConstruct(context, 'Child', {...}); new ApiService(child, 'Api', { apiName: 'grand-child' }); // 他のContextProviderが必要な場合は、ネストしていけば良い context = new DatabaseContextProvider(context, 'Default', {...}); new Database(context, 'UserDB', {...}); } }
実用的なプロジェクトでの導入例はこちらです。
ポイント
この方法のポイントは下記のとおりです:
1. Reactライクな ContextProvider パターン
Propsを渡す代わりに、ContextProvider という新しい概念を導入します。これはReactのContext APIにインスパイアされたものですが、CDKには元々コンテキストの概念があるため、存外に馴染みの良いものです。ContextProvider は、Propsを使うことなく、コンストラクトツリーの子孫にプロパティを渡すことを可能にします。
2. 暗黙の規約とエラーメッセージ
ApiService を使う際は、必ず ApiServiceContextProvider も合わせて定義する必要があります。これは暗黙の規約ですが、ユーザーはsynth時のエラーメッセージ (ApiServiceContextProvider is missing.) で容易に気づくことができます。Reactで useContext をProviderの外で使ったときと同じ体験ですね。
3. 論理IDへの影響なし
ContextProvider を作成する際は id=Default にすることで、CloudFormation論理IDに影響を与えません。これは、論理ID計算の際に、Default というidは無視されるためです (参照。) 複数種類の ContextProvider が要求される場合は、必要なContextProviderをネストさせます。この時も、すべて id=Default に設定できるので、論理IDに影響は与えません。
利点
概要は伝わりましたか?次に、この方法の嬉しさを説明します。
1. Prop drillingの解消
最大の利点は、深くネストした子コンストラクトに対して、中間層を経由せずに直接プロパティを渡せることです。中間層のPropsインターフェース定義や受け渡しコードが不要になり、コードの見通しが良くなります。
2. 型安全性
ContextProvider は型安全に利用できるため、ユーザーが誤ったコンテキストを渡すリスクを減らします。また、もし他のコンストラクトからもコンテキストを参照したい場合は、staticメソッドの getContext を使って、型安全にコンテキストを取得できます。
3. コンストラクトの独立性を向上
Propsで渡す場合、interface定義が面倒で、代わりにStackPropsをそのまま渡していくような実装も、よくしてしまいがちでした。これにより、個々のコンストラクトがStack側に依存し、プロジェクト間の再利用性が低下することもしばしばでした。
ContextProvider は、各コンストラクトライブラリがそれぞれ専用のものを提供する想定です。これにより、個々のコンストラクトは自分自身が必要とする情報のみを要求できるため、コンストラクトの独立性が保たれ、再利用性やテスタビリティが向上します。
もちろん、Propsで渡すほうが好都合なこともあるため、ContextProvider で受け取るかPropsで受け取るかは適宜判断が必要になるでしょう。実際、StackPropsをそのまま渡す実装で困ることは多くないですしね。
4. スコープの制御
コンテキストのスコープは、ContextProvider の子以下のスコープに限定されます。また、ContextProvider の子で同じ ContextProvider を作成すると、コンテキストを上書きすることもできます。これらの仕様を理解すれば、異なるコンテキストを要求する別の子コンストラクトがあっても、柔軟に値を渡すことができます。
5. 多言語対応
jsiiの規約に違反しない仕組みのため、多言語向けコンストラクトライブラリで利用することも可能です。
元々のProp drillingの例の図を書き換えると、以下のようになります。Propの受け渡しが減って見やすいですね。
欠点
欠点も考えておきます。
1つ目は、可読性・認知負荷の問題です。ContextProviderのコンストラクトを作成し、それをscopeとして別のコンストラクトを作成する実装は、あまり見慣れないものです。
let context = new ApiServiceContextProvider(this, 'Default', { environment: 'production', logBucket, }); // ここでcontextがscope(第1引数)になる new ApiService(context, 'UserApi', { apiName: 'user' });
React(JSX)的な記法で書くと以下のようなものなのですが、CDKの記法だと少しややこしくなりますね。これは慣れで解決する問題と思います。
// これが <Stack> <ApiService /> </Stack> // こうなっただけ <Stack> <ApiServiceContextProvider> <ApiService /> </ApiServiceContextProvider> </Stack>
2つ目は、id=Default を使っていることです。Default は1つのスコープに付き1度までしか使えないので、複数の ContextProvider を同じscope内で作成するときには不都合です。
const context = new ApiServiceContextProvider(this, 'Default', { environment: 'production', logBucket, }); // logBucketの異なるコンテキスト。idが被るので作成できない const context2 = new ApiServiceContextProvider(this, 'Default', { environment: 'production', logBucket: anotherLogBucket, });
今回id=Defaultは論理IDに影響を与えないようにするために使っているにすぎないので、その点を妥協すれば、他の文字列でも問題ありません。適当な短い文字列を使うのも有効でしょう。また、上記の状況が生じないように、ContextProvider経由で渡すプロパティはコンストラクト間で差の生じにくいものだけにすることも重要でしょう。
3つ目は、ContextProviderを定義するコードを、コンストラクトごとに書く必要があることです。機械的に書くことはできますが、少々面倒ですね。これはGenericsが使えれば型安全に共通化できそうですが、jsii制約下では静的に定義するしかなさそうです。15行程度の量のため、これくらいなら良いかと思っています。
// ContextProviderごとに、毎度この程度のコードが必要 export class FooContextProvider extends Construct { private static contextKey = 'foo:context'; constructor(scope: Construct, id: string, props: FooServiceContext) { super(scope, id); this.node.setContext(FooContextProvider.contextKey, props); } static getContext(scope: Construct): FooServiceContext { const context = scope.node.tryGetContext(this.contextKey); if (!context) { throw new Error('FooContextProvider is missing.'); } return context; } }
使っていくうちに他にも欠点が見えてくるかもしれませんが、今のところは、致命的な欠点は見つけられませんでした。Prop drillingが煩わしいという方、ぜひお試しください。
おわりに
1年前にこのポストをしていたのですが、ようやく良さげなアイデアが降ってきました。
AWS CDKでも、ネストされたコンストラクトへのpropsバケツリレーが煩雑になることがよくあるので、ReactのuseContext相当のAPIがあると良いかも
— Masashi Tomooka (@tmokmss) October 14, 2024
すでにcontextはあるので、より型安全なAPIで包みたいねhttps://t.co/mlc9z42NT4
いかがでしょうか?ぜひご意見ください!
今四半期のもなちゃん
3ヶ月ぶりの更新になりました 🥺 N度目の抱卵で、最近は翼がぴっちり閉じなくなってます。

背景は消しゴムマジックで消してやりました✌
AIエージェント開発 - コンテキストエンジニアリング観点でのTODOツールの良さを語りたい
AIエージェント自体の開発に関する記事です。
7月頃から、コンテキストエンジニアリングという言葉を目にする機会が増えました。これは私のAWS Summit Japanの登壇でも軽く触れましたが、エージェントへのコンテキストの与え方を工夫することで、トークン効率やタスク遂行性能、安定性など様々な面を改善しようという手法です。
Hackernewsを見ても、最近関連する投稿がやたらと増えていることが見て取れます。

おそらく出どころはエージェント開発の勘所をまとめた 12 factor agents だと思われます。この図の通り、非常に広い範囲に及ぶチューニング方法のため、正直エージェントに関するほとんどの改善施策はコンテキストエンジニアリングと言えるのではと思います。個人的には、もはやこの言葉に存在意義があるのか疑問に思うこともあります。笑

この記事では、AIエージェントにTODOツールを与えることの良さを、コンテキストエンジニアリング観点でまとめます。TODOツールとは、エージェントがタスクリストを作成し、一つずつタスクを遂行していくためのツールです。このようなTODOツールを活用するエージェントとして、Claude Codeが有名です。
Claudeのドキュメントには明示的に書かれていませんが、Claude Codeの利用者であれば、そのようなツールが使われている様子を目にしたことがあるでしょう。これこそがTODOツールの例です。

TODOツールの概要
本記事では、AIエージェントのもつTODOツールを、以下のようなツール群と定義します。
- updateTodoList ツール
- TODOリストを更新または新規作成するツールです
- ツールはファイルやDBなどに永続化され、エージェントのコンテキスト外で管理されます
- 以下のような入力を期待します:
type Input = { tasks: { title: string status: 'pending' | 'inProgress' | 'completed' }[] }
- getTodoList ツール
- 現在のTODOリストを取得するツールです
単純な2つのツールからなる仕組みですね。Claude Codeでも、似たようなツールを使ってTODOリストを管理しています。
TODOツールの何が良いか
上記のように単純な仕組みではありますが、これによりAIエージェントの挙動に関する多くの問題を解決できます。 以下に列挙していきましょう。
1. 計画立て → 実行の流れを促進できる
多くのエージェント用途において、まず全体像の計画を立ててから実行を始めることで性能が改善することはよく知られています。TODOツールがあることで、ユーザーがあまり指示せずとも、大抵このステップを踏んでくれるようになります。
Bedrockのログ機能を使うと分かりますが、 Claude CodeのTODOツールは長大なプロンプトで、TODOツールの使い方や使うべき状況、使うべきでない状況を説明しています。これくらいの説明があると、計画→実行の流れをエージェントが自ずと必要に応じて適用してくれるようになるようです。
これはどちらかというとプロンプトエンジニアリング的な観点なのですが、プロンプトもコンテキストの一種なので、コンテキストエンジニアリングに含まれますね (迫真)。
2. 計画に沿った実行を強制できる
TODOツールを使うことを選んだエージェントは、各タスクを遂行していくごとに、TODOリストを更新していきいます。
TODOリストの更新はツール内で実行されるので、エージェントの入力をコードでバリデーションし、エージェントにフィードバックできます。このバリデーションにより、エージェントの動作に、以下の大きな影響を及ぼすことができます。
例えば、以下のバリデーションです:
- 並行禁止: 同時に複数のタスクが
inProgress状態にならないようにする- これにより、エージェントが複数のタスクを同時に進めてしまうような状況を防げます
- 例えばエージェントがtask1の進行中にtask2も進めようとした場合、「task1が進行中のため、TODOリストの更新に失敗しました」とtool resultに与えることで、エージェントの軌道修正を図れるでしょう。
- 順序強制: 直前のタスクが
completed状態でない場合は、そのタスクはinProgress状態にならないようにする- これにより、当初の計画の順序を無視して、デタラメにタスクに取り組むような状況を防げます
- 例えばエージェントがtask1の完了後にtask3を進めようとした場合、「task2が未完了のため、TODOリストの更新に失敗しました」とtool resultに与えることで、エージェントの軌道修正を図れるでしょう。
AIエージェントは基本的に物忘れが激しく、直前の入力に強く影響されがちです。そのため、このような形でエージェントの実行計画にレールを敷けることの有効性は、容易に想像できるでしょう。
個人的には、このツールによるコンテキストエンジニアリングが一番好きです。似たような手法は、多くの場面で活用できる機会があります *1。
3. 未完了のタスクの完了を促せる
エージェントがTODOリストにpendingなタスクを残した状態で自分のターンを終わらせた場合、自動的にターンを再開させることも容易です。例えば、「未完了なタスクがあるので完遂してください」などとプロンプトを渡し、ターンを再開させればよいでしょう。
TODOリストをコンテキスト外で管理していれば、ユーザーの手を煩わせることなく、プログラムで自動的に実行可能であることがポイントです。
ただし、ユーザーの確認が必要などの理由でエージェントが意図してターンを終えた場合もありうるため、何らかの方法でこの挙動はエージェント側から回避できるようにもすべきでしょう。(私はこの利点を机上では思いついたのですが、その懸念があるので特にこの処理は実装していません。)
やるとしたら、これもコンテキストエンジニアリングの一種ですね!
まとめ
TODOツールの魅力をコンテキストエンジニアリング観点で紹介しました。
私の自作コーディングエージェント (Remote SWE Agents) においても、TODOツールを実装してからは、自走力が確かに増したことを実感しています。 TODOツールは実装が簡単な割に、複雑なタスクを扱う多くのAIエージェントで効果的に活用できますので、オススメです。

また、Remote SWEはAWS Summit Japanでも展示し*2、以前記事を書いたときから大きくアップグレードされています (Web UIの追加やリモートMCP対応など)。 Devin的な体験をOSS & セルフホストで実現したいという方、ぜひお試しください!
*1:Summitのセッションでは、PR作成ツールの例を紹介しました。複数の問題を一網打尽にできた、気持ちの良いチューニングです。
*2:クラスメソッドの方がレポート記事を書いていただきました!
AIエージェントアプリのコンテキスト長上限回避方法まとめ
LLMの基盤モデルには、コンテキスト長の上限があります。例えばClaude4では20万トークンが上限で、これを超えるトークン数を入力するとエラーになります。
一方、昨今のAIエージェントアプリでは、複雑なタスクを任せる場合、エージェントとユーザー・ツールとの間で多くのやり取りが生じます。この結果、コンテキスト長が上限を超えるほどメッセージ履歴が長くなることも珍しくありません。上限を超えた後もエージェントとのやり取りを継続するためには、何らかの方法で上限を回避する方法があります。
本記事では、メッセージ履歴が上限を超えるほど長くなったときに、その上限を回避する方法の選択肢をまとめます。
方法1. Sliding window
最も単純な方法で、直近N件のメッセージのみをコンテキストに渡す方法です。窓がスライドするようにエージェントから見えるメッセージのスライスがズレていくので、sliding windowと呼ばれたりします。
これにより、(1メッセージで大きなトークンを消費するメッセージがないとすれば) 全体のトークン長が上限を超えることは防ぐことができます。

ただし、注意点はいくつかあります:
1. プロンプトキャッシュとの相性
メッセージを追加するたびにウィンドウをずらす場合、メッセージ配列におけるプロンプトキャッシュが実質無効化されてしまいます。これは非常に非効率です。

このため、実際はLLM APIコールのたびに1つずつずらすのではなく、何回かをまとめてずらす必要があるでしょう。

例えば上記の図では、sliding windowを適用する際にMessage 51からではなく71から始めることで、50-30=20件まではプロンプトキャッシュが有効な状態・かつウィンドウ長が50件以内に収まるようにトークンを入力できるようにしています。
2. トークン数かメッセージ件数か
先ほど「1メッセージで大きなトークンを消費するメッセージがないとすれば」という条件をつけましたが、この条件が満たされない場合は、この方法はうまく機能しません。極端な例を挙げると、1メッセージのトークン数が平均50kトークンを超える場合は、Claudeなら4メッセージだけで上限を超えることになります。
ユースケースが決まっており、1メッセージの平均トークン数が既知の場合はこのままでも良いですが、そうではない場合は改善が必要です。より適応的にするためには、トークン数の合計でsliding windowのサイズを決めると良いでしょう。例えばAnthropic APIでは、あるメッセージのトークン数を計算するAPIがあるため、容易に実現できます。BedrockだとこのようなAPIは現状ありませんが、Converse APIのレスポンスに含まれる消費トークン数の情報から、各メッセージのトークン数を概算することが可能です (実装はやや複雑です)。
各メッセージのトークン数がわかれば、例えばトークン数の合計を計算することで、sliding windowの長さを調節することができます。
方法2. Middle-out
Sliding windowはメジャーな方法ですが、用途によっては、前方のメッセージが重要であり、コンテキストから除外したくない場合もあります。例えば、1つのセッションで1つの問題解決を行うコーディングエージェントでは、最初のメッセージで問題が与えられることが多く、このとき序盤のやり取りは特に重要となります。
このような場合に適するのがmiddle-outです。OpenRouterのドキュメントでそのように言及されていました。
これはメッセージ履歴の中央部をコンテキストから除外する方法です。下図ではMessage 11~59が除外されていることに注目してください。

パラメータとして、前方のメッセージを取る件数と、後方のメッセージを取る件数の2つがあります。大抵は、後方のほうを多めにするのが良さそうです。 また、sliding windowと同じく、プロンプトキャッシュの考慮は必要ですし、トークン数で件数を動的に調節するのも有効です。
Sliding windowは、Middle-outの前方件数を0にしたものとみなせます。Middle-outを実装すれば自ずとSliding windowも実装できたことになるので、お得ですね。
ただし、「序盤のやり取りが特に重要」かどうかはユースケースに依存するため、例えば1セッション内で複数の異なるタスクを指示するユーザーにとっては、この方法が非効率となりえる点は注意です。
方法3. Condenser
方法1/2ともに、コンテキストから除外されるメッセージは、LLMにとっては完全に忘れ去られる(=存在しなかった)のと同義です。これでは、ユーザーとのそれまでのやり取りや過去のツールの実行結果を忘れてしまい、あまり賢くない印象を与えてしまうリスクがあります。
この対策として、メッセージを除外するのではなく、要約して圧縮する方法がCondenserです。由来はOpenHandsがこう呼んでいましたが、Amazon Q Developer CLIでは似た機能がcompactコマンドとして提供されています。

実装は1や2と比べて複雑になりますし、要約のため追加のLLM APIコールが必要になりますが、忘却対策には効果的かもしれません。
補足. 長期記憶
忘却対策の別解として、長期記憶の導入が考えられます。これは例えば以下のような方法です:
- 会話履歴をDBに保存する。ユーザーがメッセージを送るたびに過去の会話履歴から関連するメッセージを取り出し、コンテキストに含める。例えばMastraのsemantic recallのような機能です。
- 遂行すべきタスクなど、重要な情報をファイルとして保存する。このファイルの内容は、常にコンテキストに載せるようにする。例えばclaude-task-masterというMCPサーバーがあります。
直接的にコンテキスト長制御の方法となるわけではありませんが、例えばSliding windowと長期記憶を併用すれば、コンテキストを良い感じに管理できるはずです。
まとめ
エージェントアプリでは頻出の悩みである、コンテキスト長上限の回避方法をいくつかまとめました。これを実装すれば、無限に一つのエージェントとやり取りができるようになるので、ぜひ実装してみてください。コンテキスト長制御は、Amazon Bedrockだとトークン数のQuota回避にも役立つので、おすすめです。
最近はこういった下回りはエージェント開発フレームワークに任せれば良い説もありますが、仕組みを知っているだけでも、エージェント開発時だけでなく利用時にも役立つはずです。
ちなみに私の開発するRemote SWE Agentsでは、middle-outをトークン数ベースで実装しています。このエージェントも、Claude 4により更に自走力が上がっているので、ぜひお試しください。