AWS Lambdaのコールドスタートはアプリ開発でしばしば悩まされる問題です。この記事では、特にPythonのLambda関数 (コンテナも含む) において、コールドスタートが遅い際の対処方法をいくつか紹介します (注意: 網羅は目指してません)。
第一歩: 計測する
Pythonプログラムのコールドスタートが遅い場合、モジュール群のインポートに時間が掛かっていることが多いと思います。
モジュールのインポートに要する時間は次の方法で計測・可視化できます。
まず、-X importtime オプション付きでPythonプログラムを実行します。Lambda環境そのもので実行する*1のはログの取得が面倒なので、最初はローカル環境で実行して良いでしょう。厳密には異なると思われますが、十分良い近似を出してくれるはずです。
このオプションにより、標準エラー出力に以下のような形式のテキストが出力されます:
import time: self [us] | cumulative | imported package import time: 86 | 86 | _io import time: 16 | 16 | marshal import time: 177 | 177 | posix ...
次のコマンドなどを利用して、上記の出力をファイルに保存しましょう:
python -X importtime main.py 2> prof.txt
importtimeの結果は読みづらいので、別のツールで可視化します。今回はtunaを使います。
tunaはpipからインストールでき、上記で得られた出力を渡すことで利用できます。
pip install tuna tuna prof.txt
解析が終わると自動的にウェブブラウザが起動し、結果が可視化されます。Framegraphに似た形式です。
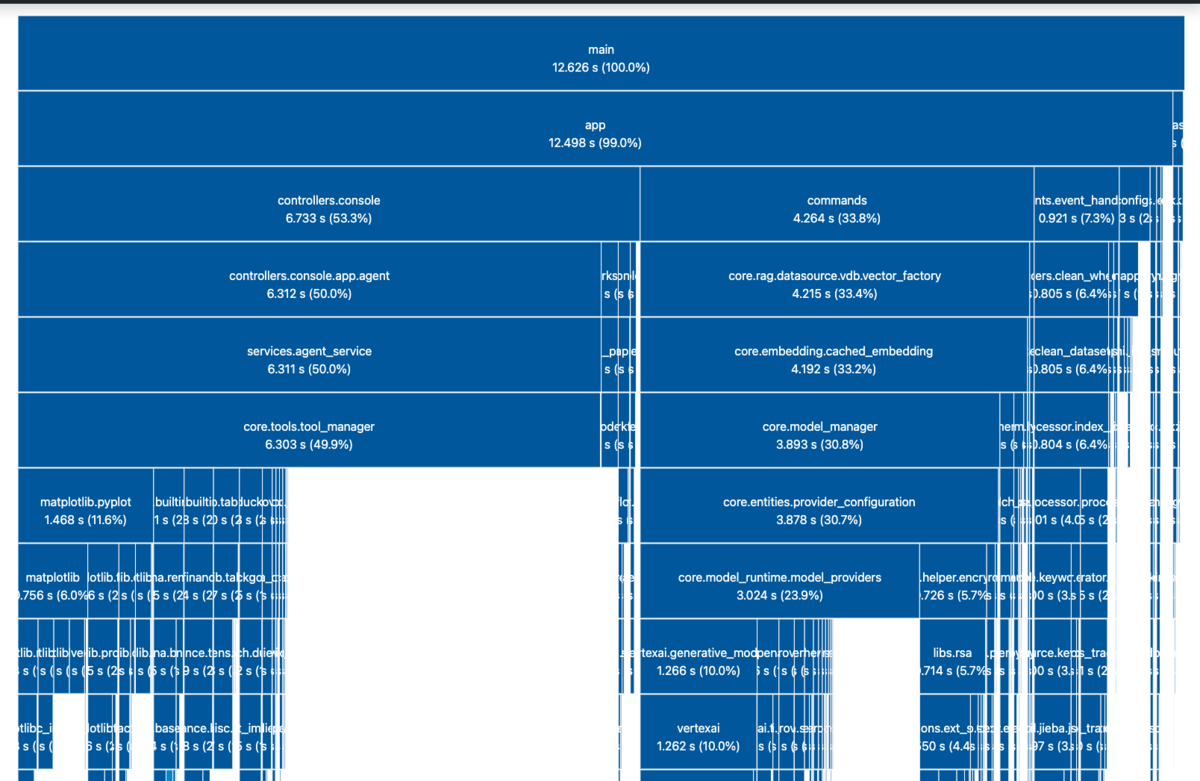
インポートされるモジュールはツリー構造を成します。一番上がrootのモジュールで、下に行くほど親からインポートされる子のモジュールになります。横幅がインポートにかかる時間の長さを示します。
それでは、この結果を元に対処方法を考えていきましょう。
対処方法
基本的には、インポート時間の長いモジュールに対処していくことになります。
大まかには、以下の方法があるでしょう:
- モジュールを遅延ロードする
- モジュールの初期化処理を変更する
- モジュールへの依存をやめる
それぞれ詳細をまとめます:
1. モジュールを遅延ロードする
Pythonのimport文は通常ファイルの頭に書きますが、ローカルスコープに書くこともできます。これにより、import処理の実行がそのスコープに入ったときに遅延されるため、プログラム自体の初期化時間には影響を与えなくなります。
この方法は、初期化後もめったに使われないようなモジュールでは有効です。
例えば以下の vertexai.generative_models は、インポートに1秒以上要している割に、VertexAIを利用するとき以外は不要なモジュールと考えられるため、遅延ロードの効果は大きいでしょう。

一方で頻繁に利用されるモジュールでは、初期化処理の後にすぐにインポート処理が走ることが多いと考えられるため、あまり効果がないことも多いでしょう。ただし、Lambdaでは初期化処理が10秒を超えると初期化が中断・再実行されるという仕様があります (参照)。これを避けるため、遅延ロードにより初期化処理を10秒未満に収めるという方法が有効な場合もあるでしょう。
Pythonにおける遅延ロードの実装パターンはこちらにまとまっていました: Lazy import in Python
上記の記事の要点をまとめます。まず、オリジナルのコードが下記だとします:
import foo def func(): foo.bar()
import文を実行時に移動すれば、遅延ロードが実現できます:
def func(): import foo foo.bar()
なお、インポート処理が走るのは最初の一度だけなので、func関数の初回の呼び出し時は遅くなりますが、それ以降はパフォーマンスが下がるということはありません。
importlib を使えば、インポートされたモジュールを変数に格納することもできます。複数のスコープでモジュールを共有したい場合は使えそうです:
from importlib import import_module def init(): global foo foo = import_module('foo') # 以下はinitの呼び出し後のみ使える def funcA(): foo.barA() def funcB(): foo.barB()
ただし、type annotationにおいては直接インポートされたモジュールのみ参照できる (変数は不可) ようで、遅延読み込みされた型を使う方法がなさそうでした。この辺りの議論を見る限り、まだできないような気がしています。Pythonに詳しい方の知見をお待ちしております。
# foo.BarTypeは遅延読み込みできる? def func() -> foo.BarType: foo.bar()
2. モジュールの初期化処理を変更する
モジュールによっては、importされた際に時間のかかる処理を実行するものがあります。極端な例は下記です:
# foo.py import time time.sleep(10) # main.py import foo # これで10秒待つことに
自作のモジュールであれば、こうした時間のかかる処理を消す・あるいは初期化後に移動することができるか検討すると良いでしょう。
例えば、下図の core.tools.tool_manager のように、子のインポートではなく自分自身で時間が掛かっている場合は、このパターンのはずです。

3. モジュールへの依存をやめる
どうしようもないモジュール (ライブラリ) は、代替手段を考えるのも良いですね。
以降は少し毛色は違いますが、別解として書いておきます。
4. __pycache__ をデプロイパッケージに含める
Pythonはモジュールがインポートされた際に、pyファイルをコンパイルしたバイトコードのキャッシュを __pycache__ フォルダに生成します。これにより、次回実行時には高速な初期化を実現できます。
しかしLambdaでは1つの実行環境では1度しか初期化されないため、__pycache__ の恩恵は受けづらいです。では、事前に生成してパッケージに埋め込んでおけばどうでしょうか?
その方法には落とし穴があります。バイトコードは環境依存のため、ローカル端末で作成した __pycache__ をLambda環境で使えるとは限らないことです。このため、zipデプロイではLambdaパッケージに含めないことが明確に推奨されています*2。
We recommend that you don't include __pycache__ folders in your function's deployment package. Python bytecode that's compiled on a build machine with a different architecture or operating system might not be compatible with the Lambda execution environment.
しかし、コンテナLambdaでは話は変わると思われます。コンテナ内で __pycache__ を生成すれば、OSやアーキテクチャの差異は発生しないはずのためです。
実際にDifyで試したところ、コールドスタート時間は60%ほどまで短くなりました (40秒 → 25秒)。効果は抜群です。__pycache__ の恩恵は、ローカルでも .venv を作り直して実行するなどすれば、実感することができるでしょう。
__pycache__ の生成には、compileall を利用できます。以下はDifyにおけるDockerfileの例です:
FROM langgenius/dify-api RUN python -m compileall -f -j 0 -q ./ || true
compileallは、引数で渡したフォルダに対して再帰的にpyファイルを探してコンパイルします。対象にすべきフォルダは環境により異なる可能性があるので、適宜確認してください (-q フラグを外すと、処理対象のファイルパスが出力されます。)
また、今回は特定のライブラリのコンパイルでエラーが発生することがあったので、|| true でエラーを無視しています。
この方法だと、コード自体は変更不要なのも良い点ですね。
5. Lambda関数を分割する
Lambdalithは一部で流行りの方法ですが、複数の機能を一つのLambda関数にまとめる都合上、インポートするモジュールが増えコールドスタートが長くなりがちです。
私はこれがLambdalithの最も大きな欠点だと考えています。Lambdalithはメリットが多いため積極的に採用すべきだと考えますが、コールドスタートがあまりにも長くなったときは対策が必要です。Lambda関数を分割しましょう。
分割の方針を決めるには、各機能が利用するモジュールを観察し、効果的な境界を見出します。すべての機能で遍く使われるライブラリではなく、一部の機能でのみ利用されるライブラリに注目するのがコツです。
分割の実装自体はそれほど大変ではないことも多いです。例えばFastAPIではルーターを機能ごとに定義し、エントリポイントから必要なルーターだけをインポートして使うことができます。これにより、1つのFastAPIアプリケーションを複数に分割することは容易です。
Lambda関数へのルーティングは、Amazon API GatewayやCloudFront (FURLの場合) などを使うと良いでしょう。
6. 何回か起動してみる
Docker Lambdaの場合は、Lambdaサービス側でのイメージキャッシュの持ち方の都合 (参考) で、何度かコールドスタートさせると時間が短くなる可能性があります。
デプロイ後初回のコールドスタートで遅かったからといって、それだけで判断するのは禁物です。複数回のコールドスタートの平均値を見ましょう。また、Productionでのメトリクスも参考にすると良いでしょう。
まとめ
Python Lambdaのコールドスタート時間の解析方法・改善方法を紹介しました。ぜひ試してみてください。 (PythonにもSnapStartがほしくなりますね)