AWS CDK TIpsシリーズの記事です。
AWS CDKのスタック、まとめてますか?分けてますか?分けている方はどういう基準で分けていますか?
この議論は人によって割と意見の分かれることも多く、最高の飲み会ネタになるでしょう。今日は私見も交えながら、CDKのスタック分割法についてまとめてみたいと思います。
自己紹介
私見を語る上で自己紹介は必要だと思うので、私自身のCDK経験を簡潔に:
CDKは2020年の頭に出会い、以下のようにかれこれ3年ほど使っています。
- 前職ではそれなり規模のmBaaSをCDKを使ってAWSに移行・運用していました
- 現職では大小様々な規模のプロトタイプ開発にCDKを使っています。数えるとこれまで15個くらいシステムのプロトタイプを作ったようです。
- 現職のサイドプロジェクトとして、グローバル規模の社内システムの開発運用もCDKでやってました (お手伝い程度)。AWSアカウント管理用サービスで、ユーザーがアカウントを作るたびに26+リージョン全てにCDKスタックをデプロイするみたいな面白い使い方をしてました。
- AWS CDK本体へのコントリビューションもたまに取り組んでいます。
元々バックエンド開発が生業だったので CloudFormationよりもすんなりと入れた記憶です。今日はこれまでの経験も踏まえながら、考えをまとめてみます。
早速、個人的にベストと思うスタックの分け方
必要がないなら分けない! これが基本ルールだと考えます。
理由: スタックを分けると、大抵の場合スタック間に依存関係が生じます。スタック間でリソースを参照することで発生するスタック間参照によるものです。そしてCDK開発ではあるあるですが、この依存関係によって開発・運用上面倒が生じることが多いです (後述)。このデメリットが通常大きいので、必要ない限りは単一スタックに保つのが良いと考えています。
「必要がないなら」ということは、どういうときに分ける必要があるかが問題です。これはCloudFormationの制約に引っかかるときだと考えていて、具体的には以下の状況です:
- リソース数が500を超えるとき
- CloudFormation のクォータによる制限です
- 例えばこんなとき:
- 非常に大規模なシステム
- サーバーレスのAPIでルートごとにLambdaを分けているとき
- マルチアカウント、マルチリージョン
- リソースをデプロイする間にCloudFormation外の操作が必要なとき
上記の状況にあたらない場合は、スタックを分ける必要はないので、単一スタックにまとめた方が良いと考えています。
スタックを分けることで生じる問題
さきほどスタックを分けると面倒が生じがちと書きましたが、具体的にはどういう問題でしょうか。これは主に以下の点です:
1. リソースの変更・削除時に新たに考慮事項が生じる
これはCDKではよく知られたハマリポイントです。例えば以下の状況を考えましょう。ParentStackとChildStackがあり、ParentStackの中のDynamoDBテーブルをChildStackのLambda関数が Fn::ImportValue で参照しているとします。

この状況でChildStackからLambda関数を削除します。するとCDKは同時に、参照されなくなったDynamoDBテーブルのStack exportをParentStackから削除しますね。この合成されたテンプレートをデプロイしてみましょう。
CDKはスタック間に依存関係がある場合、依存関係の親のスタックからデプロイします。これは多くの場合都合が良い挙動です。従って今回はParentStackからデプロイされますが、この時点ではChildStackはまだLambda関数が残っているので、Stack exportも利用されています。すると使用中のStack exportは削除できないので、デプロイに失敗してしまうのです。
この問題はよく知られた問題なので、対処方法はいくつかあります:
- 依存関係を無視してデプロイする (
--exclusivelyフラグ) - スタック間参照を使わずにパラメータを受け渡す
- 明示的にStack exportを作成して、削除されるのを防ぐ
- Weak reference (まだRFC段階)
対処できるとはいえ、煩雑なのは変わりありません。必要がない限り意識したいものではなく、スタックを分けない大きな理由になるでしょう。
2. スタック間の循環依存を回避する必要がある
CloudFormationはスタック間の循環依存を許可しないため、循環依存が発生しないように注意してCDKを書く必要があります。循環依存とは、例えば以下が同時に成立する状況です:
- スタックA内のリソース1aがスタックB内のリソース1bに依存
- スタックB内のリソース2bがスタックA内のリソース1aに依存
この時スタックAとBは循環依存となり、CDKが合成時に検知してエラーとなります。注意して実装すれば大抵回避できるのですが、まれにL2コンストラクトの実装が原因で回避が難しいことがありました。例えば、こちらのIssueは好例です。
CDKのL2実装が成熟するにつれてこうした問題は減ってきているとは思いますが、いずれにせよスタックを分けることで新たに考慮が必要になる問題ではあるので、デメリットとして挙げました。
3. デプロイが遅くなる
CDKによるデプロイでは、依存関係のあるスタックは並列にデプロイすることができません。代わりに、直列に1スタックずつデプロイすることになります。一方単一スタック内のデプロイは、CloudFormationがリソース間の依存関係を見て互いに依存しないリソースは並列デプロイされます。
このために、単一スタックで全てデプロイする場合と比べてデプロイの並列度が下がり、トータルではより長い時間がかかるようになります。
特に開発環境では変更をすぐにデプロイしてより高速にイテレーションを回したいことが多く、デプロイ時間は短いほど良いことが多いでしょう。デプロイを俊敏にするという意味でも、スタックの不必要な分割は避けたいものです。
4. 適切な分け方を考えるのが大変
そもそもですが、上記のような問題も考慮に入れながら適切なスタックの分割方法を考えるのは非常に大変です。まして、明確に分ける必要が無い状況下ではなおさらです。必要がないのにどういう基準で分けるというのでしょうか?
KISSの原則というものもありますが、必要ない限り単純に保つのというのは多くの場合無難な選択肢でしょう。スタックの数が少ないほど複雑度が低いというのはCDK開発者の共通認識だと思います。複雑度はできるだけ低く保ちたいですよね。
以上、スタックを分けると生じがちな厄介事でした。分けることで上記のデメリットを上回るメリットがあるのなら、分けましょう。とはいえ個人的な経験から言えば、冒頭に挙げたスタックを分けざるを得ない状況以外では、分けるメリットが上回ることは少ないのではないかと思います。
分けるときはどう分けると良いか
というわけで 基本的には分けない というのが私の考える基本ルールです。とはいえ、上述の制限に引っかかるような状況ではスタックを分けざるを得ないこともあります。この時にどう分けるのが良いのかも考えてみましょう。
スタックを分けるデメリットを先ほどまとめましたが、これらのデメリットができるだけ顕出しないような分け方が良い分け方だと言えるでしょう。4は不可避なので、特に1~3の観点で考えます。
スタックを分けるデメリット (再掲) 1. リソースの変更・削除時に新たに考慮事項が生じる 2. スタック間の循環依存 3. デプロイが遅くなる 4. 適切な分け方を考えるのが大変
1については、抑制するためにはできるだけスタック間参照の数を減らすことが重要になりそうです。リソースの依存がスタックをまたがないようにすることで、リソース追加・削除時の考慮を減らしましょう。2も同様にスタック間参照が減れば良いでしょう。3については、スタック間の依存関係を考えて、直列に依存するスタックをできるだけ減らすのが重要でしょう。
では具体例として、以下のようなシステムを考えてみます。青い四角形がシステム内に存在するAWSリソース、矢印がリソース間の依存関係と考えてください。左側はECSやALB、SQSによるサービス、右側はDDB, Lambdaなどによる別のサービス、VPCやRDSが共有リソースとして存在するような構成です。

この時、例えば以下2つのスタック分割法を検討してみましょう:
- AWSサービスのカテゴリによる分け方
- システム内における責務による分け方
- 共通部分とサービス固有部分に分け、それぞれでスタックを分ける方法です
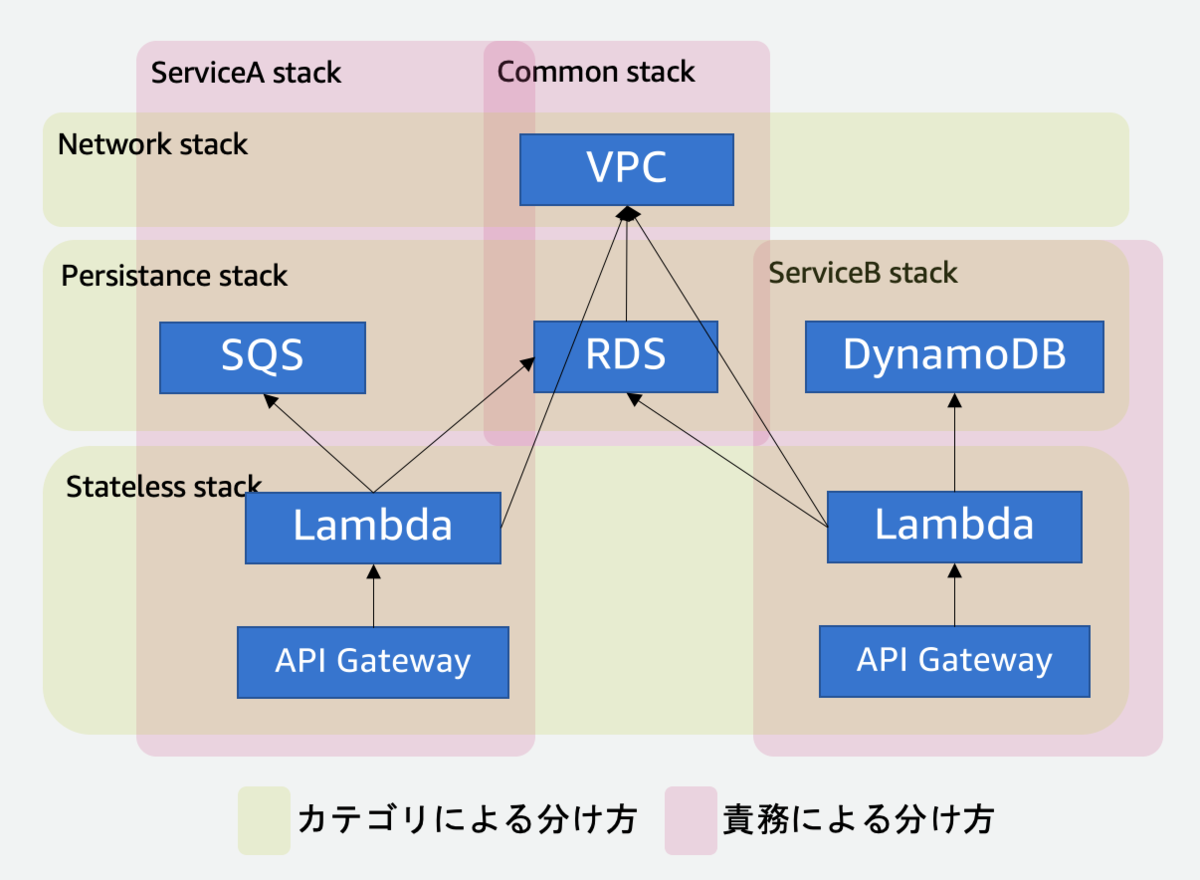
この2つを比べると、後者の方がより良い分け方だと考えられます。理由を説明するため、スタック間の依存グラフやスタック間参照の数を具体的に図示してみましょう。

前者の分け方はすべてのスタックが直列に依存しており、デプロイの並列度は低いです。また、スタック間参照の数も多く、例えばSQSやDynamoDBのリソースを変更しようとした時に、デプロイが失敗してしまう可能性があります。
一方後者の分け方は、少なくともServiceA/Bスタックは互いに依存しないため、並列デプロイが可能です。また、こちらはSQSやDynamoDBなどのリソースへの依存はスタック内に閉じているので、変更時のデプロイが比較的容易です (もちろんステートフルゆえの考慮事項はありますが。)
上記は極めて単純化したケースで、実際はCDKのL2コンストラクトが思わぬスタック間参照を作ることもありすべてを見越して分割するのはなかなか大変ではあるのですが、基本的には上のようなことを考えながらスタックを分けるとより良くなっていくと思います。また同時に、この辺りの議論はあまり成熟しておらず人によって意見が分かれる部分なのではとも思います。同意という方もここはこうしているという方も、ぜひご意見お聞かせください!
まとめ
- AWS CDKにおけるスタックの分け方について考え方をまとめました。
- 必要のない限り分けない が原則だと考えています!
- 分けるときはできるだけデメリットがないような分け方をしましょう
FAQ
ついでによく耳にするツッコミについても考えてみました。以下にまとめます。
ライフサイクルによりスタックを分けるべき?
CloudFormationのベストプラクティス では、スタックをライフサイクルやオーナーシップで分けることが推奨されています。ここはCDKだと若干異なる部分だと考えています。CloudFormationを手で書いている場合だと、スタックの依存関係も手動管理になるはずなので、あまり上で挙げたようなデメリットを感じづらいのかもしれません。
Organize your stacks by lifecycle and ownership
まずオーナーシップでスタックを分けるという点については、CDKだとむしろAppやリポジトリレベルで分けるのが良いでしょう。異なるチームが同じCDKのレポジトリを触りデプロイも一緒に行うのは、多くの場合得策ではないためです。結果的には、Appが分かれるのでスタックも自ずと分かれます。
ライフサイクルで分けるという点については、CDKだとやはり上述の分けることによるデメリットがあるので、必ず分ける理由にはならないと考えます。更新頻度が異なるリソースはスタックを分けるべきという方もいますが、めったに更新されないリソースと頻繁に更新されるリソースが同一スタック内に同居していても特に問題はありません。重要なリソースに意図しない変更が反映される可能性を減らしたいという方もいますが、それはそもそもCIで差分管理すべきですし、いずれにせよ同じApp内であれば依存関係のあるスタックはすべてデプロイされてしまいます。
とりあえずライフサイクルの違いでスタックを分けているという方は、今一度それによりどういうメリットがあるのかを再考してみても良いかもしれませんね。
Nested stackはどうなの?
個人的にあまり使った経験がないので多くを語れないのですが、基本的にはスタックと同じ制約を課されるはずなので、これも分けない(=使わない)のが良いのではと思います。ただし一部のL2コンストラクト (EKSなど) では標準的に使われているので、うまく使えるなら良いのかもしれません。Nested stack派の方の意見も伺いたいものです。
スタックを一つにまとめるとコードが見づらくならない?
CDK開発者の中には、Stackクラスのコンストラクタにリソースをベタ書きする派の方もいるようです。この場合、スタック内のリソースが増えるにつれてコンストラクタのコードが長大になり、可読性が下がると行った問題が生じる可能性があります。
これを回避するためには、CDKのコンストラクトを使ってコードを構造化しましょう。一例としてはこのようなコードです: コード例。 ここについてはいろいろなノウハウがあるので、また追加で記事を書きたいと思います。